

После того как президент упомянул KazLLM, в новостях появилось много цитат, но почти не было объяснений. Что это за модель? Кто её создавал? Зачем она стране?
KazLLM называют первой казахстанской большой языковой моделью. В официальных материалах разработчиком проекта указан ISSAI - Институт интеллектуальных систем при Nazarbayev University, исследовательский центр, специализирующийся на машинном обучении и ИИ-технологиях. Логично было обратиться именно к разработчикам. Редакция Astana Plus направила в ISSAI официальный запрос и получила развернутые письменные ответы.
KazLLM называют первой казахстанской большой языковой моделью. В официальных материалах разработчиком проекта указан ISSAI - Институт интеллектуальных систем при Nazarbayev University, исследовательский центр, специализирующийся на машинном обучении и ИИ-технологиях. Логично было обратиться именно к разработчикам. Редакция Astana Plus направила в ISSAI официальный запрос и получила развернутые письменные ответы.
Ниже - полный текст письменных ответов ISSAI в формате «вопрос — ответ».
Почему страны разрабатывают собственные LLM?
Генеративный ИИ, и особенно большие языковые модели (LLM), сегодня стали одной из наиболее стратегически значимых технологических областей в мире. LLM — это уже не просто исследовательские инструменты: это базовая цифровая инфраструктура. Они используются в поисковых системах, образовательных платформах, корпоративном ПО, государственных услугах, системах национальной безопасности и инструментах нового поколения для повышения продуктивности. Страны, которые разрабатывают и осваивают фундаментальные модели, по сути формируют собственные будущие цифровые экосистемы, инновационный потенциал и долгосрочную экономическую конкурентоспособность.
Генеративный ИИ, и особенно большие языковые модели (LLM), сегодня стали одной из наиболее стратегически значимых технологических областей в мире. LLM — это уже не просто исследовательские инструменты: это базовая цифровая инфраструктура. Они используются в поисковых системах, образовательных платформах, корпоративном ПО, государственных услугах, системах национальной безопасности и инструментах нового поколения для повышения продуктивности. Страны, которые разрабатывают и осваивают фундаментальные модели, по сути формируют собственные будущие цифровые экосистемы, инновационный потенциал и долгосрочную экономическую конкурентоспособность.
Масштаб глобальных инвестиций ясно показывает стратегическую значимость этого направления. Крупнейшие технологические компании выделяют беспрецедентные ресурсы на генеративный ИИ. Сама OpenAI объявляла планы потратить десятки миллиардов долларов на вычислительную инфраструктуру, дата-центры и обучение моделей в ближайшие годы. Эти инвестиции отражают инфраструктурные и исследовательские обязательства глобального уровня.
Однако LLM - это не только про технологический прогресс, но и про технологический суверенитет. Страны всё чаще понимают, что опора исключительно на зарубежные ИИ-системы создаёт стратегическую зависимость - в управлении данными, вопросах безопасности, удержании экономической ценности внутри страны и согласованности с локальным регулированием.
Ниже институт приводит примеры стран, которые уже создали собственные национальные языковые модели.
Таблица 1. Примеры национальных больших языковых моделей и их ключевых суверенных особенностей
Закономерность очевидна: ведущие экономики рассматривают LLM как критическую инфраструктуру. Разработка собственных моделей ИИ позволяет странам сохранять языковую и культурную представленность, обеспечивать безопасность данных и соответствие требованиям регулирования, удерживать экономическую ценность внутри национальной экосистемы, снижать технологическую зависимость от внешних геополитических факторов, а также развивать местные кадры в сфере ИИ и наращивать вычислительные мощности.
Что такое KazLLM и зачем она была создана?
Большая языковая модель - это ИИ-технология, обученная на огромных объёмах текстовых данных, чтобы предсказывать каждое следующее слово в определенной последовательности. Когда человек задаёт вопрос, модель генерирует контекстно правдоподобный ответ. Такие системы, как ChatGPT, построены вокруг подобного типа моделей.
Полезная аналогия — представить большую языковую модель как двигатель. Сам двигатель не является готовым транспортным средством, но это ключевой механизм, который обеспечивает работу всего остального. Один и тот же двигатель может приводить в движение разные виды транспорта — например, внедорожник, легковой автомобиль, трактор или микроавтобус — в зависимости от того, как он интегрирован и развернут.
Большая языковая модель - это ИИ-технология, обученная на огромных объёмах текстовых данных, чтобы предсказывать каждое следующее слово в определенной последовательности. Когда человек задаёт вопрос, модель генерирует контекстно правдоподобный ответ. Такие системы, как ChatGPT, построены вокруг подобного типа моделей.
Полезная аналогия — представить большую языковую модель как двигатель. Сам двигатель не является готовым транспортным средством, но это ключевой механизм, который обеспечивает работу всего остального. Один и тот же двигатель может приводить в движение разные виды транспорта — например, внедорожник, легковой автомобиль, трактор или микроавтобус — в зависимости от того, как он интегрирован и развернут.
Аналогично, KazLLM — это базовый технологический компонент ИИ-ассистентов и чат-ботов. Вокруг него можно создавать приложения: государственные ассистенты, корпоративные чат-боты или образовательные платформы. В этом смысле сама модель — это «двигатель», а практические сервисы требуют дополнительной разработки, дообучения, интеграции с базами данных и инструментами, а также инфраструктуры для масштабного развертывания. ISSAI получил задачу создать именно этот «двигатель». Мы не участвовали в разработке и/или эксплуатации пользовательских приложений или сервисов на его основе.
Кто стоит за созданием KazLLM? Что это за команда и почему она взялась за такой проект?
KazLLM была разработана Институтом умных систем и искусственного интеллекта (ISSAI) при Назарбаев Университете в период с апреля 2024 года по декабрь 2024 года. Команда состоит из молодых казахстанских исследователей, специализирующихся в машинном обучении, data science и компьютерной инженерии. Проект реализовывался в сотрудничестве с ключевыми национальными партнёрами, включая Министерство ИИ и Цифрового развития, Министерство науки и высшего образования, АО «Национальные информационные технологии», Национальный научно-практический центр «Тіл-Қазына», QazCode (Beeline), MIND Group (Университет имени М. Нарикбаева), а также ведущие университеты и научные институты страны.
KazLLM была разработана Институтом умных систем и искусственного интеллекта (ISSAI) при Назарбаев Университете в период с апреля 2024 года по декабрь 2024 года. Команда состоит из молодых казахстанских исследователей, специализирующихся в машинном обучении, data science и компьютерной инженерии. Проект реализовывался в сотрудничестве с ключевыми национальными партнёрами, включая Министерство ИИ и Цифрового развития, Министерство науки и высшего образования, АО «Национальные информационные технологии», Национальный научно-практический центр «Тіл-Қазына», QazCode (Beeline), MIND Group (Университет имени М. Нарикбаева), а также ведущие университеты и научные институты страны.

Одной из ключевых задач ISSAI было не только создать модель, но и сформировать национальную экспертизу. Разработка KazLLM потребовала собрать высококачественные базы данных, настроить полный цикл обучения модели, провести научные исследования и получить практический опыт разработки моделей большого масштаба. Эти компетенции критически важны для долгосрочной технологической независимости.

ISSAI разработал две версии KazLLM: модель на 8 млрд. параметров для использования на рабочих станциях и модель на 70 млрд. параметров для развёртывания (deployment) в на мощных серверах. В качестве основы была выбрана архитектура Llama 3.1, поскольку на тот момент это была одна из сильнейших открытых архитектур в мире. Например, SEA-LION крупная модель для Юго-Восточной Азии, выпущенная AI Singapore в декабре 2024 года, также основывалась на архитектурах семейства Llama. Проект SEA-LION является программой большого масштаб, т.к. Сингапур выделил на его реализацию около 52 млн. долларов США.
Во многих странах разработку генеративных моделей ведут крупные технологические компании (OpenAI — ChatGPT, Alibaba — Qwen, Meta — Llama, Anthropic — Claude, DeepseekAI — DeepSeek). Однако, в Казахстане доля затрат частного сектора на R&D в процентах от ВВП относительно низкая, и такие работы обычно не выполняются бизнесом. Именно поэтому государство обратилось к академическому исследовательскому институту.
Какова производительность KazLLM?
Международная практика предполагает бенчмаркинг подобных моделей. Модель ISSAI KazLLM оценивалась по стандартным, широко используемым тестам, которые комплексно измеряют понимание языка, навыки решения задач, фактологические знания и общее качество рассуждений. Часть бенчмарков была адаптирована под казахский язык. Выпущенные модели KazLLM превзошли соответствующие исходные версии модели Llama по агрегированному показателю. На момент релиза (декабрь 2024 года) KazLLM 70B почти достигла метрик, демонстрируемых GPT-4o
Международная практика предполагает бенчмаркинг подобных моделей. Модель ISSAI KazLLM оценивалась по стандартным, широко используемым тестам, которые комплексно измеряют понимание языка, навыки решения задач, фактологические знания и общее качество рассуждений. Часть бенчмарков была адаптирована под казахский язык. Выпущенные модели KazLLM превзошли соответствующие исходные версии модели Llama по агрегированному показателю. На момент релиза (декабрь 2024 года) KazLLM 70B почти достигла метрик, демонстрируемых GPT-4o
Далее — оценка производительности модели по данным ISSAI.
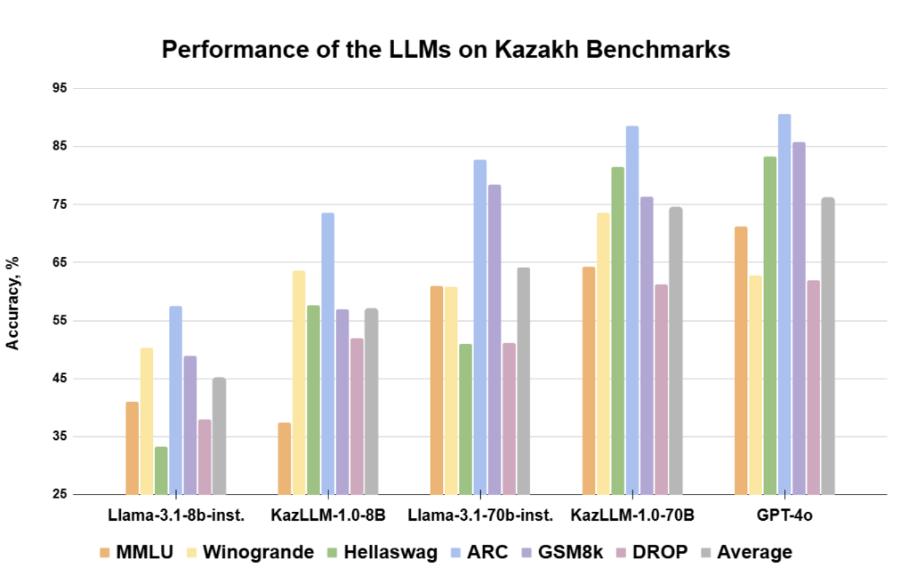
Таблица 2. Бенчмарки производительности LLM на казахском языке
Однако ИИ — это гонка и новые модели появляются примерно каждые шесть месяцев, соответственно и KazLLM необходимо развивать дальше. После передачи модели в Astana Hub в декабре 2024 года вопрос о дальнейшей разработки и усовершенствования KazLLM перед нами не поднимался.
KazLLM была создана, чтобы Казахстан сформировал компетенции в генеративном ИИ, укрепил исследовательский потенциал и развил интеллектуальный капитал, необходимый для участия в этой глобальной технологической трансформации.
Кроме того, международные лидеры и эксперты отметили усилия Казахстана по созданию собственной национальной модели. Пионер ИИ-исследований Янн ЛеКун упомянул результаты KazLLM в начале 2025 г. Чуть позже, на престижной церемонии GSMA Foundry Excellence Awards 2025 KazLLM получила награду.
Кроме того, международные лидеры и эксперты отметили усилия Казахстана по созданию собственной национальной модели. Пионер ИИ-исследований Янн ЛеКун упомянул результаты KazLLM в начале 2025 г. Чуть позже, на престижной церемонии GSMA Foundry Excellence Awards 2025 KazLLM получила награду.
Почему Казахстану нужна собственная языковая модель?
ISSAI последовательно выступал за создание локальных решений для ИИ-потребностей Казахстана. Однако формальный запрос на разработку KazLLM поступил от Государства. По мере того как ИИ всё сильнее влияет на госуслуги, бизнес-процессы и доступ к информации, стало ясно, что опора исключительно на зарубежные решения создаёт стратегическую зависимость. Разработка локальной модели гарантирует, что Казахстан понимает базовую технологию и может адаптировать её при необходимости.
ISSAI последовательно выступал за создание локальных решений для ИИ-потребностей Казахстана. Однако формальный запрос на разработку KazLLM поступил от Государства. По мере того как ИИ всё сильнее влияет на госуслуги, бизнес-процессы и доступ к информации, стало ясно, что опора исключительно на зарубежные решения создаёт стратегическую зависимость. Разработка локальной модели гарантирует, что Казахстан понимает базовую технологию и может адаптировать её при необходимости.

Многие сравнивают KazLLM с ChatGPT. В чём принципиальная разница?
ChatGPT — это законченный продукт и сервисная экосистема. Он объединяет несколько версий больших языковых моделей, интеллектуальные системы маршрутизации, веб-поиск, базы данных, слои безопасности и модерации и разворачивается на масштабной глобальной инфраструктуре дата-центров. Он постоянно обновляется на основе пользовательской обратной связи и прогресса в исследованиях. Важно и то, что за ним стоят крупные финансовые инвестиции. Например, ежегодные операционные и инфраструктурные расходы OpenAI, как ожидается, достигнут порядка 1,4 трлн. долларов, что отражает масштаб ресурсов, необходимых для обучения и поддержки подобных систем. Такой уровень финансирования позволяет непрерывно улучшать модели и обеспечивать глобальное развертывание. (Цифры и оценки приведены по данным, указанным в ответе ISSAI.)

Соответственно, все перечисленные выше разработки требуют существенных и долгосрочных финансовых вложений. Простая аналогия: KazLLM — это двигатель, а ChatGPT — полностью собранный и отполированный автомобиль, который постоянно обновляемый и обслуживаемый.
Кто может использовать KazLLM?
KazLLM широко используется в исследовательских целях, что подтверждается загрузками из открытых репозиториев (https://huggingface.co/issai). Исследователи и разработчики применяют её как основу для дальнейших инноваций. Поскольку в декабре 2024 года в Astana Hub была передана неисключительная лицензия, нам неизвестны текущие планы по дальнейшему применению и развитию.
KazLLM широко используется в исследовательских целях, что подтверждается загрузками из открытых репозиториев (https://huggingface.co/issai). Исследователи и разработчики применяют её как основу для дальнейших инноваций. Поскольку в декабре 2024 года в Astana Hub была передана неисключительная лицензия, нам неизвестны текущие планы по дальнейшему применению и развитию.

Примеры того, как такие модели могут упростить жизнь
Практический пример — взаимодействие с государственными сервисами. Вместо поиска нужного раздела на сложных сайтах гражданин мог бы описать запрос и получить структурированную подсказку (например, через ИИ чат-бота). В образовании студенты могли бы получать объяснения научных концепций на казахском языке, адаптированные под их уровень. В бизнесе компании могли бы автоматизировать подготовку документов или управление внутренними знаниями. Эти примеры показывают, как генеративный ИИ повышает доступность и эффективность.
Практический пример — взаимодействие с государственными сервисами. Вместо поиска нужного раздела на сложных сайтах гражданин мог бы описать запрос и получить структурированную подсказку (например, через ИИ чат-бота). В образовании студенты могли бы получать объяснения научных концепций на казахском языке, адаптированные под их уровень. В бизнесе компании могли бы автоматизировать подготовку документов или управление внутренними знаниями. Эти примеры показывают, как генеративный ИИ повышает доступность и эффективность.
Какое самое распространённое заблуждение о KazLLM и языковых моделях?
Чтобы оставаться конкурентоспособными, необходимы постоянные инвестиции и исследования. Именно поэтому технологически развитые страны (Израиль, Южная Корея, Швеция, США и др.) выделяют высокий процент ВВП на R&D (научно-исследовательские и опытно-конструкторские работы), а быстро развивающиеся страны со средним уровнем дохода также тратят более 1% ВВП на R&D (в то время как в Казахстане около 0,2%).
Чтобы оставаться конкурентоспособными, необходимы постоянные инвестиции и исследования. Именно поэтому технологически развитые страны (Израиль, Южная Корея, Швеция, США и др.) выделяют высокий процент ВВП на R&D (научно-исследовательские и опытно-конструкторские работы), а быстро развивающиеся страны со средним уровнем дохода также тратят более 1% ВВП на R&D (в то время как в Казахстане около 0,2%).
Распространённое заблуждение состоит в том, что выпуск модели — это финальное или долговечное достижение.
В действительности генеративный ИИ развивается очень быстро регулярно появляются новые архитектуры и методы обучения. С момента появления KazLLM произошёл целый ряд значимых прорывов (архитектуры Mixture-of-Experts, «reasoning-модели», мультимодальные LLM, предсказание нескольких токенов и т. п.). За последние 13 месяцев OpenAI выпустила около 5 крупных версий GPT (включая GPT-4.1, 4.5 и обновления серии GPT-5), а Alibaba представила примерно 7 крупных вариантов/семейств моделей (включая серии Qwen2.5 и Qwen3). Команде R&D необходимо постоянно обновлять данные, дообучать модель с учётом новых архитектур и выпускать новые версии. Это похоже на автомобильную индустрию, но с намного более быстрым темпом.
Одним из наиболее заметных примеров инвестиций частного сектора в генеративный ИИ в нашем регионе является Сбербанк (Российская Федерация), который разрабатывает и внедряет собственную линейку ИИ-моделей и инструментов. Его решения, такие как GigaChat, создаются как конкурент глобальным LLM и интегрируются в различные отрасли, с планами расширять возможности и доступность, включая открытые релизы продвинутых моделей (например, GigaChat 3 Ultra Preview) и других флагманских систем.
Сбербанк также публично заявлял о внушительных инвестиционных планах в ИИ, намереваясь существенно увеличить расходы в этой области, чтобы трансформировать технологический контур и получить значимую отдачу от этих технологий.
Сбербанк также публично заявлял о внушительных инвестиционных планах в ИИ, намереваясь существенно увеличить расходы в этой области, чтобы трансформировать технологический контур и получить значимую отдачу от этих технологий.
С учётом такого прецедента, а также сильных финансовых результатов банковского сектора Казахстана, существует очевидная возможность для казахстанских финансовых институтов инвестировать в развитие отечественного генеративного ИИ, особенно в открытые модели, которые можно адаптировать и развивать локально. Такое стратегическое инвестирование могло бы не только поддержать технологический суверенитет, но и усилить конкурентоспособность и инновационность цифровой экономики страны.
Могут ли обычные пользователи использовать KazLLM в повседневной жизни?
Да, но большие модели требуют значительной вычислительной инфраструктуры. Обучение и масштабное развертывание зависят от высокопроизводительных дата-центров, и в мире идёт интенсивная конкуренция за создание такой инфраструктуры. Без масштабного развертывания фундаментальная модель не сможет эффективно обслуживать массовую аудиторию. Потенциально ИИ-агенты или чат-боты, построенные вокруг этой модели, могут быть размещены на новых суперкомпьютерах в Казахстане (AlemCloud, Al-Farabium). Если новые суперкомпьютеры не будут полностью загружены другими важными сервисами и моделями, то, возможно, модели вроде KazLLM удастся развернуть и открыть для широкой аудитории, чтобы собирать пользовательскую обратную связь.
Да, но большие модели требуют значительной вычислительной инфраструктуры. Обучение и масштабное развертывание зависят от высокопроизводительных дата-центров, и в мире идёт интенсивная конкуренция за создание такой инфраструктуры. Без масштабного развертывания фундаментальная модель не сможет эффективно обслуживать массовую аудиторию. Потенциально ИИ-агенты или чат-боты, построенные вокруг этой модели, могут быть размещены на новых суперкомпьютерах в Казахстане (AlemCloud, Al-Farabium). Если новые суперкомпьютеры не будут полностью загружены другими важными сервисами и моделями, то, возможно, модели вроде KazLLM удастся развернуть и открыть для широкой аудитории, чтобы собирать пользовательскую обратную связь.

Можно ли увидеть KazLLM в действии сегодня?
Назарбаев Университет передал неисключительную лицензию в Astana Hub в конце декабря 2024 года. Развертывание зависит от инфраструктуры и операционных решений обладателя лицензии, нам неизвестны текущие планы по дальнейшему применению и развитию KazLLM.
Назарбаев Университет передал неисключительную лицензию в Astana Hub в конце декабря 2024 года. Развертывание зависит от инфраструктуры и операционных решений обладателя лицензии, нам неизвестны текущие планы по дальнейшему применению и развитию KazLLM.
Как решать проблемы с “галлюцинациями” и ошибками?
Все генеративные модели могут выдавать неточные ответы. Снижение рисков требует интеграции механизмов верификации, например, обращения к базам данных (retrieval), веб-поиска, защитных «ограждений» (guardrails) и систем пользовательской обратной связи. Одна модель сама по себе не гарантирует надёжность, ответственное развертывание требует создания полноценного продукта вокруг неё.
Все генеративные модели могут выдавать неточные ответы. Снижение рисков требует интеграции механизмов верификации, например, обращения к базам данных (retrieval), веб-поиска, защитных «ограждений» (guardrails) и систем пользовательской обратной связи. Одна модель сама по себе не гарантирует надёжность, ответственное развертывание требует создания полноценного продукта вокруг неё.
После развертывания генеративных моделей взаимодействие с пользователями становится критически важным источником инсайтов. Каждый вопрос, каждая попытка выполнить задачу или оценка ответа дают ценные данные о том, как модель ведёт себя в реальных сценариях. Эти взаимодействия постоянно мониторятся, анализируются и возвращаются в цикл разработки продукта, чтобы выявлять типовые ошибки, пробелы в знаниях или ситуации, где рассуждения модели недостаточно качественны.
Коммерческие сервисы, построенные на таких моделях, опираются на этот цикл обратной связи, чтобы обновлять и улучшать поведение модели, повышать точность и улучшать пользовательский опыт. Например, улучшения могут включать дообучение отдельных компонентов, настройку параметров, совершенствование промптов или добавление механизмов проверки таких как retrieval и веб-поиск.
Однако этот процесс трудоёмок и требует человеческих, вычислительных и финансовых ресурсов. Команды инженеров, аналитиков данных, модераторов данных и менеджеры по развитию продуктов должны просматривать взаимодействия, классифицировать ошибки, расставлять приоритеты и внедрять улучшения. Кроме того, человеческий контроль обеспечивает этичное и безопасное использование, соблюдение требований регулирования и соответствие корпоративным и общественным стандартам. Без такой системной работы модели не могут надёжно эволюционировать до уровня, необходимого для практического использования и коммерческого качества.
Как эти технологии повлияют на образование и рынок труда?
Генеративный ИИ изменит многие профессии, автоматизируя рутинные когнитивные задачи. Страны, которые развивают собственную экспертизу, с большей вероятностью получат экономические преимущества. Те, кто полностью зависит от внешних систем, могут столкнуться с более сильными негативными эффектами и дисбалансами.
Есть ли сферы, где использование языковых моделей опасно?
Существуют риски как долгосрочного, так и среднесрочного характера. Известные эксперты, включая лауреата Turing Award Джеффри Хинтона, предупреждали о потенциальных экзистенциальных рисках от продвинутых ИИ-систем. Историк Юваль Ной Харари также отмечал, что ИИ может быть опаснее ядерного оружия, но в отличие от атомной бомбы продвинутый ИИ способен действовать автономно и принимать решения без человеческого контроля. Хотя долгосрочные экзистенциальные и общественные риски требуют серьёзного управления и надзора, существуют значимые среднесрочные риски: дипфейки, дезинформация, киберпреступность и, что особенно важно, технологическая стагнация. Страны и институты, которые не смогут ответственно развивать и осваивать ИИ-технологии, рискуют потерять конкурентоспособность, технологический суверенитет и стратегическое влияние в мире, всё более управляемом ИИ.
Существуют риски как долгосрочного, так и среднесрочного характера. Известные эксперты, включая лауреата Turing Award Джеффри Хинтона, предупреждали о потенциальных экзистенциальных рисках от продвинутых ИИ-систем. Историк Юваль Ной Харари также отмечал, что ИИ может быть опаснее ядерного оружия, но в отличие от атомной бомбы продвинутый ИИ способен действовать автономно и принимать решения без человеческого контроля. Хотя долгосрочные экзистенциальные и общественные риски требуют серьёзного управления и надзора, существуют значимые среднесрочные риски: дипфейки, дезинформация, киберпреступность и, что особенно важно, технологическая стагнация. Страны и институты, которые не смогут ответственно развивать и осваивать ИИ-технологии, рискуют потерять конкурентоспособность, технологический суверенитет и стратегическое влияние в мире, всё более управляемом ИИ.
Как обычные граждане могут помочь?
Текущая парадигма ИИ это машинное обучение: в этой парадигме модели учатся на данных. Если гражданин Казахстана создаёт публичные данные на казахском языке (например, статью в Википедии), локальные и глобальные ИИ-модели смогут использовать этот контент в обучении и «будут знать» больше о Казахстане и казахском языке. Поэтому человек, который хочет помочь, может создавать релевантный Казахстану контент на казахском языке.
Во-вторых, многие технологические гиганты предоставляют модели по низкой цене или бесплатно не просто так, а потому что хотят собирать обратную связь и реальные кейсы использования. Поэтому использование локальных моделей (Oylan, MangiSoz) и предоставление отзывов внесет ценный вклад в их дальнейшее развитие и улучшение.
Текущая парадигма ИИ это машинное обучение: в этой парадигме модели учатся на данных. Если гражданин Казахстана создаёт публичные данные на казахском языке (например, статью в Википедии), локальные и глобальные ИИ-модели смогут использовать этот контент в обучении и «будут знать» больше о Казахстане и казахском языке. Поэтому человек, который хочет помочь, может создавать релевантный Казахстану контент на казахском языке.
Во-вторых, многие технологические гиганты предоставляют модели по низкой цене или бесплатно не просто так, а потому что хотят собирать обратную связь и реальные кейсы использования. Поэтому использование локальных моделей (Oylan, MangiSoz) и предоставление отзывов внесет ценный вклад в их дальнейшее развитие и улучшение.
ОТ РЕДАКЦИИ
Материал публикуется без сокращений. Редакция Astana Plus продолжит следить за развитием проекта KazLLM и его практическим применением.
